This note deals with state-of-the-art methodologies in prompt tuning and addresses some distinctions between different methods used in different research.
This note compares methodologies of five papers and what they do namely:
- L2P : Learning to Prompt for Continual Learning 2022
- CPP : Steering Prototypes with Prompt-tuning for Rehearsal-free Continual Learning 2023
- CODA-P: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning 2023
- MLCIL: Dynamic Prompt Adjustment for Multi-Label Class-Incremental Learning 2024
The first paper is in a single task setting while the others are in CIL.
CIL questions for prompt tuning: How do we perform continual learning with two core concepts - plasticity + stability? How do we generate prompts and how to create an objective function? What about the input to the models and how to optimize?
Summaries
Methodologies
Prompt Pool and Selection
Prompts - Just like Prompt Tuning (PT) in NLP where they use frozen transformer models for downstream tasks prepended to input tokens, here prompts are learnable embedding vectors.
Key - Value based (L2P)
- L2P - Keys learnt via a keys to query loss function
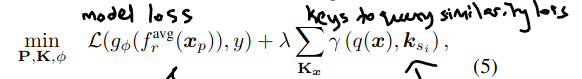
- To choose diverse prompts, a penalty term added to the equation, based on a prompt frequency table.
- They are task-agnostic and keys are just selected by minimizing the input.
Prompt Components (CODA-P)
- CODA-P - Weighted summation of individual prompt components to calculate the final prompt.
- The keys to prompts are learned by using a clustering technique by projecting into a latent dimensional space.
- Each component has an attention vector which works like a feature selector in the latent space.
- Prompt component, attention and key compared with the query for obtaining weights for the prompt component. In essence, the contribution of each prompt component can determine the final prompt, which is determined by the similarity between the query and the key.
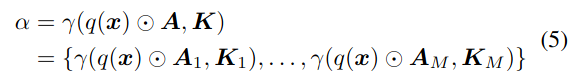
- Again, task-agnostic.
Contrastive Prototypical Loss (CPP)
- CPP: CLP technique done to combat interference and to cluster classes within a task.
- Interference - Classes from prior tasks overlapping with current tasks because of close embedding values in a space.;.
- Objective? Cluster together intra-task classes while avoiding interference.
- Prototypes - Multi-centroid embeddings for each class taken (in place of just mean distribution from class). The embeddings are taken by using pairwise cosine sim between each class embedding and then spectral clustering performed to get C no. of centroids.
- These prototypes are used for performing CPL.
- Negative anchors - classes from previous tasks, negative embeddings - classes in current task thats not associated with a prototype, positive embeddings - current task, current class.
- Prototypes decoupled into two items: Key - which uses the multi-centroid embeddings value C which used for querying, and Value - its the task specific prompt embedding for the particular class.
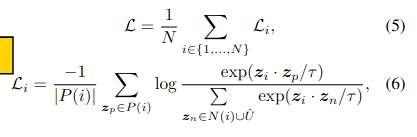
- During learning, the distance between query vector and the Value prototype are minimized.
- Deep Prompt used, so they append the prompts to S layers.
Dual Prompting (TaIDPT)
- In a zero shot setting - text descriptions available for images in a dataset are used for generating class labels by performing a noun filtering. Done by stemming the nouns in the description sentences, and then matches with a synonym table to find appropriate class variables.
- Two prompts are learnt while maximizing the similarity between the input image and the ground truth classes - global embedding which takes the global text and image embeddings and a local embedding for fine grained features which is useful in a multiclass setting where minority classes are to be identified as well in images.

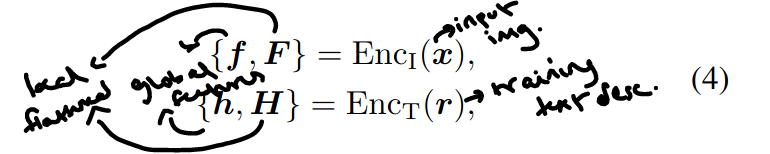
- They use two copies of the Enc_t(r) encoder which comes from CLIP's text encoder for each prompt. Then the global features f, h for image and text embeddings are respectively caluclated along with F, H for local.
- During training, the prompt parameters are trained and during testing, the class embeddings are obtained. During training only text descriptions are used for the training, and during texting the image is mapped with the classes and hence visual features are used. They argue that just using the classes in text embeddings are enough for the training and visual features are not needed.
Incremental Context Prompt (MLCIL)
- MLCIL - Uses two different prompts: category specific and context specific.
- Aim for using two prompts? To reduce class specific bias.
- Each takes word embeddings representative of each learned class and the context respectively.
- Feature selection performed by using image encoder and a text encoder in CLIP.
- Three output feature vectors obtained from these models - fx (visual features of image x for the respective classes), gc (textual features flr category specific prompts), gs (context specific).
- CFA - Class specific region feature aggregation - image features extracted for each relevant category
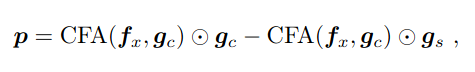
- They aggregate the text features and image features by projecting the image features into textual feature space.
Catastropic forgetting specific methods
Expansion and Orthogonality (CODA-P)
- CODA-P: Freezes past components an only updating new components and expanding the set.
- To reduce interference, they use orthognality constraint to the Prompt, Key and Attention. Its included as a penalty term in the loss.
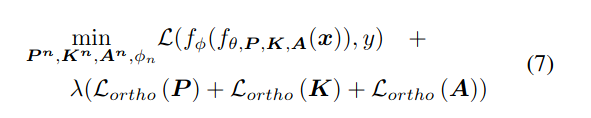
Selective Confidence Cluster Replay (MLCIL)
- MLCIL: Clusters of positive samples are obtained and then confidence based cluster sampling is done.
- Purpose - It basically retrains k number of hard samples selected within a cluster and they are retrained.
- These k samples are chosen by their lowest predicted probability from the text encoder.
Datasets & Models
Datasets
- MS-COCO
- PASCAL VOC
Models
- CLIP