L1 Personalized Lexical Complexity Prediction (LCP) for German-language-learners
Psycholinguistics | Second Language Acquisition (SLA) | Deep Learning
Word Complexity is a perceived notion of difficulty of different words in a language, subjective to one's individual prior experiences. Lexical Complexity Prediction (LCP) is an NLP subtask that predicts the difficulty of words in a given context on a dynamic scale. There has been growing research into how LCP can be incorporated predicting personalized scored for different subjects. This project utilizes an LCP dataset to build a predictive model for generating personalized difficulty scores of different words. LCP is an important research in the field of Computational Linguistics (CL) and Natural Language Processing (NLP) and has applications for assisting second-language-learners, children and individuals with low-literacy-rates. This project was done in conjugation with Ferdinand Steinbeis Research Institute and University of Stuttgart.
Task
In this regression task of determining on a continuous scale of 0 to 1 the difficulty of words in a given context depending on the individual's language backgrounds, a neural ensemble model was developed utilizing a novel ensemble model for LCP.
Technologies
Pytorch FastAI transformers
Description of data
The dataset used in this project consists of the following variables:
word: The target word whose complexity is being predicted.context: The sentence or phrase in which the target word appears.user_id: A unique identifier for each participant in the study.native_language: The native language of the participant.proficiency_level: The self-reported proficiency level of the participant in the target language (e.g., beginner, intermediate, advanced).complexity_score: The perceived complexity score of the target word, rated on a scale from 0 to 1.
Generic model description
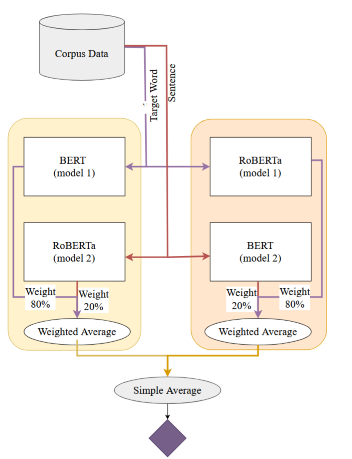 The model was an extension of the JUST-BLUE ensemble architecture presented by Yaseen et al. 2021 1. To handle categorical features describing a subject, an additional learner-specific embedding layer was incorporated into the ensemble model. This extension allows the model to account for personalized information, improving predictions by adapting the complexity score to the individual’s language profile.
The model was an extension of the JUST-BLUE ensemble architecture presented by Yaseen et al. 2021 1. To handle categorical features describing a subject, an additional learner-specific embedding layer was incorporated into the ensemble model. This extension allows the model to account for personalized information, improving predictions by adapting the complexity score to the individual’s language profile.
Personalized Features
An important aspect of this architecture is the inclusion of learner-specific contextual features, with relation to a learner's language background, demographic and life experiences, and language-specific features about the morphological features of the context word and the psycholinguistic features including prior exposure of the word with the speaker. A fundamental challenge lies in transforming discrete categorical features into continuous vector representations that can interact meaningfully with text embeddings in Transformer models.
Traditional Approaches
Traditional models that include one-hot encoding or label encoding are sub-optimal solutions that do not carry all the semantic information. Dahouda and Joe (2021) 2 show that these techniques could lead to very high vector dimensional representations. Utilizing categorical features as separate tokens could also hinder with our ability to pass in more information into BERT models given their shorter sequence lengths of upto 512 characters. This post describes a comprehensive way of converting categorical features into text. An example of such is shown below: In this way, for instance numerical features can be converted into running sentences with semantic information. The example below follows the example provided in the post.
| Feature | Example Value |
|---|---|
| Clothing ID | 123 |
| Department Name | Dresses |
| Division Name | General |
| Class Name | Dresses |
| Age | 34 |
| Rating | 5 |
| Recommended IND | 1 |
The table above can be converted into the following continuous text:
This item comes from the Dresses department. It belongs to the General division. It is classified under Dresses. I am 34 years old. I rate this item 5 out of 5 stars.
This methodology can help LLMs like BERT to infer relationships from natural language. However, when we utilize complex features tha are in large number, the model would start performing poor given it's short context length, as well as its inability to interpret the minute differences in a large range of real number feature values.
Embedding layer
Results
| Model | MAE | RMSE | Spearmans | Pearsons |
|---|---|---|---|---|
| BERT | 0.236 | 0.271 | 0.182 | 0.260 |
| RoBERTa | 0.186 | 0.276 | 0.293 | 0.276 |
| JUST-BLUE | 0.210 | 0.243 | 0.282 | 0.252 |
| BERT + cat_features | 0.258 | 0.321 | -0.054 | -0.148 |
| RoBERTa + cat_features | 0.186 | 0.203 | 0.391 | 0.360 |
| JUST-BLUE + cat_features | 0.224 | 0.252 | 0.130 | 0.143 |
References
Footnotes
-
Tuqa Bani Yaseen, Qusai Ismail, Sarah Al-Omari, Eslam Al-Sobh, and Malak Abdullah. 2021. JUST-BLUE at SemEval-2021 task 1: Predicting lexical complexity using BERT and RoBERTa pre-trained language models. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 661–666, Online. Association for Computational Linguistics. ↩
-
M. K. Dahouda and I. Joe, "A Deep-Learned Embedding Technique for Categorical Features Encoding," in IEEE Access, vol. 9, pp. 114381-114391, 2021, doi: 10.1109/ACCESS.2021.3104357. ↩