KG-based Recommender System for Industrial Data
Knowledge Graphs | Natural Language Understanding (NLU) | Vector Database
Ciao✌ There has been SIGNIFICANT development in my work with Knowledge GRaphs, and in this article I will detail a lot of what I have been doing.
Problem Statement
A lot of industries rely on archaic hand crafted manuals that are used as references when operating heavy machines, here in Germany. These are primarily in German but industrial equipments from foreign countries send English content too. There are a lot of these! For someone who's just starting, these can all seem overwhelming and often would rely on a person monitoring their activities until they get used to these machines.
A reliable chat system is the solution for this, for someone to adapt to these systems without scouring through pages and pages of content trying to look for one specific question they might have when they are still getting accustomed to such machines. This would also be better than having to slow productivity by asking other personnel at work.
This chat system needs to not just be useful but also reliable, quick and must answer A LOT of questions. Now, for RAG.
Importance of RAG in Modern NLP
- A critical aspect of RAG’s importance lies in its ability to mitigate hallucinations in generative models. Traditional language models often generate plausible but incorrect information due to their reliance on static training data. RAG addresses this by incorporating a retrieval component that grounds responses in real-time, external knowledge sources, ensuring factual accuracy.
- RAG: has a retrieval and a generation engine.
- Queries and documents in a shared embedding (semantic) space transformed into high-dimensional vectors.
- For the generator, cross-attention mechanisms are pivotal.
- One overlooked factor is retrieval noise—irrelevant documents retrieved due to embedding errors. Addressing this with re-ranking models or filtering heuristics can significantly enhance output quality.
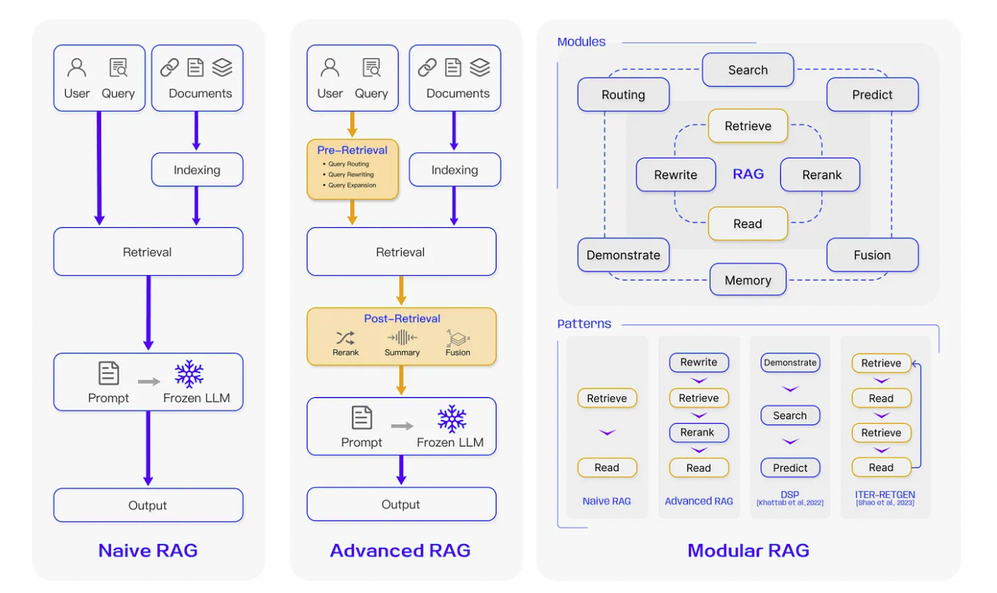
- Retrieval bias - the system disproportionately favors certain sources. Addressing this requires diversity-aware retrieval algorithms to ensure balanced outputs.
- Retrieval quality directly impacts the generative output. For instance, in healthcare, retrieving peer-reviewed studies instead of general articles can drastically improve the accuracy of medical advice.
High-level architecture (flow)
-
Data sources -> There's two different data sources: one primarily from hand-crafted content from German industries with machine operating manuals, tool builders, registries etc. and the second is available ontologies online that can provide relational information.
-
Preprocessing & canonicalization -> This is pretty straight-forward stuff. LLMs do these very easily, but since our systems rely on old NLP parsers, we use
StanfordNLPandspacyfor this. -
Entity extraction / linking & RDF import (
neosemanticsto import RDF). Graph Database & Analytics -> This is a giant step that can be trained with modern neural networks combined with traditional heuristics. There is excellent research into Entity Linking right now and the most common ones use hybrid approaches. -
Embedding generation -> The main idea is to generate chunks with the data. And then refine data into what is required in the KG.
-
Persist into Neo4j -> For now graph storage and access can be done with neo4j and cypher query offered by neo4j. Graph Database & Analytics
-
LangChain retrieval pipeline -> While we are still discussing how to perform the vector search and retrieval, we have settled with utilizing langchain for now. We have the problem of speed and efficiency and would require something more robust for so in our pipeline. LangChain Python API
-
Output: ranked list of evidence items + provenance (node ids, cypher snippets, score metadata) ready to feed the LLM.
-
Evaluation -> This is an important step as our pipeline has to be quick, not too large, easily accesible, utilize smaller GPUs like 1050 and have good high recall.
Semantic-web (RDF/OWL) and Neo4j (n10s)
Input: RDF Turtles / RDF endpoint / ontology files.
Output: Neo4j nodes/relationships modeling triples and preserving ontology terms (classes, properties).
Unstructured data and neo4j (chunkung)
Input: DB records, PDF/TXT/DOCX, support tickets, knowledge base articles.
Output: document chunks with metadata (source id, offset, language, created_at).
## Generate embeddings for chunks and/or nodes
**Input:** document chunks, node summaries (short, 1–3 sentences)
**Output:** numeric embedding vectors stored in Neo4j (as a property) and indexed with Neo4j Vector index.
**Embedding models:**
- **Cloud APIs:** OpenAI's GPT-3 (expensive and large); Llama (better open source option)
- **Local / sentence-transformers:** `all-mpnet-base-v2`; smaller `all-MiniLM` for cost control.
## Persist chunks and link to KG in Neo4j
**Input:** chunk text + metadata + embedding + entity links
**Output:** nodes and edges in Neo4j ready for vector search and graph traversal.